


















公告
随缘更新不定内容,敬请期待!!!
2748 words
14 minutes
基于 MobileNetV2 的垃圾图像分类
基于 MobileNetV2 的垃圾图像分类
写在前面
总算考完转专业考试了,考完也是立马补上了这个实验。
一、实验目的与要求
- 理解图像分类任务与目标检测任务的区别,掌握分类网络的基本原理。
- 了解迁移学习(Transfer Learning)的概念:利用在大规模数据集上预训练好的模型,在小数据集上快速微调,以较少的训练时间获得较好的分类效果。
- 掌握使用 PyTorch 框架加载 MobileNetV2 预训练模型并替换分类头的方法。
- 能够在无 GPU 的普通电脑上完成垃圾图像分类模型的训练与预测,理解训练过程中损失值与准确率的变化规律。(本实验实际使用 NVIDIA RTX 5070 GPU 加速)
- 学会对预测结果进行可视化分析,判断模型在各类别上的表现差异。
二、实验方法与步骤
1. 激活已有虚拟环境并安装依赖
直接复用之前实验的 yolo11 虚拟环境,打开 Anaconda Prompt:
conda activate yolo11pip install torch torchvision matplotlib scikit-learn seaborn2. 准备数据集
本实验使用已准备好的垃圾分类数据集,包含 10 个类别: 电池(battery)、生物(biological)、纸板(cardboard)、衣物(clothes)、玻璃(glass)、金属(metal)、纸张(paper)、塑料(plastic)、鞋子(shoes)、其他垃圾(trash)。(本次数据集从阿里云下载)
将数据集与脚本放到如下位置:
项目文件夹/ train.py predict.py garbage-dataset/ battery/ biological/ cardboard/ clothes/ glass/ metal/ paper/ plastic/ shoes/ trash/3. 编写并运行训练脚本
新建 train.py,核心内容:
import torchimport torch.nn as nnfrom torchvision import datasets, transforms, modelsfrom torch.utils.data import DataLoader, Subsetfrom sklearn.metrics import classification_report
# 数据预处理train_transform = transforms.Compose([ transforms.Resize((128, 128)), transforms.RandomHorizontalFlip(), transforms.RandomRotation(15), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
val_transform = transforms.Compose([ transforms.Resize((128, 128)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
# 加载数据集(10个类别,共19762张图片,8:2划分)data_dir = "./garbage-dataset"train_data = datasets.ImageFolder(data_dir, transform=train_transform)val_data = datasets.ImageFolder(data_dir, transform=val_transform)class_names = train_data.classes
n_total = len(train_data)n_train = int(n_total * 0.8)n_val = n_total - n_trainindices = torch.randperm(n_total).tolist()train_set = Subset(train_data, indices[:n_train])val_set = Subset(val_data, indices[n_train:])train_loader = DataLoader(train_set, batch_size=16, shuffle=True)val_loader = DataLoader(val_set, batch_size=16, shuffle=False)
# 加载预训练模型并修改分类头model = models.mobilenet_v2(weights='IMAGENET1K_V1')for param in model.features.parameters(): param.requires_grad = Falsemodel.classifier[1] = nn.Linear(model.last_channel, len(class_names))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = model.to(device)
# 训练配置criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.classifier.parameters(), lr=0.001)EPOCHS = 10best_acc = 0.0
for epoch in range(EPOCHS): # 训练阶段 model.train() total_loss = 0 correct = 0 for imgs, labels in train_loader: imgs, labels = imgs.to(device), labels.to(device) optimizer.zero_grad() outputs = model(imgs) loss = criterion(outputs, labels) loss.backward() optimizer.step() total_loss += loss.item() correct += (outputs.argmax(1) == labels).sum().item() train_acc = correct / n_train
# 验证阶段 model.eval() val_correct = 0 with torch.no_grad(): for imgs, labels in val_loader: imgs, labels = imgs.to(device), labels.to(device) outputs = model(imgs) val_correct += (outputs.argmax(1) == labels).sum().item() val_acc = val_correct / n_val
print(f"Epoch {epoch+1}/{EPOCHS} | Loss: {total_loss/len(train_loader):.3f} | Train Acc: {train_acc:.3f} | Val Acc: {val_acc:.3f}") if val_acc > best_acc: best_acc = val_acc torch.save(model.state_dict(), 'best_model.pth')
print(f"最佳验证准确率: {best_acc:.3f}")其中第一次训练的时候是没有用GPU的,后面才加上的GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = model.to(device)这个是直接用CPU的版本
device = torch.device('cpu')model = model.to(device)然后是预测与验证的事:
4. 编写并运行预测脚本
同目录下新建 predict.py:
import torchimport torch.nn as nnfrom torchvision import transforms, modelsfrom PIL import Imageimport matplotlib.pyplot as plt
class_names = ['battery', 'biological', 'cardboard', 'clothes', 'glass', 'metal', 'paper', 'plastic', 'shoes', 'trash']
model = models.mobilenet_v2(weights=None)model.classifier[1] = nn.Linear(model.last_channel, len(class_names))model.load_state_dict(torch.load('best_model.pth', map_location='cpu'))model.eval()
transform = transforms.Compose([ transforms.Resize((128, 128)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
img_path = 'test.jpg'img = Image.open(img_path).convert('RGB')tensor = transform(img).unsqueeze(0)
with torch.no_grad(): outputs = model(tensor) probs = torch.softmax(outputs, dim=1)[0] pred = probs.argmax().item()
print(f"预测结果: {class_names[pred]}")print(f"置信度: {probs[pred]:.2%}")
plt.figure(figsize=(5,5))plt.imshow(img)plt.axis('off')plt.title(f"预测: {class_names[pred]}\n置信度: {probs[pred]:.2%}")plt.savefig('result.jpg')plt.show()然后开WSL运行:
python predict.py实验过程及内容
1. 训练过程记录(10个epoch)
| Epoch | Loss | Train Acc | Val Acc |
|---|---|---|---|
| 1 | 0.811 | 0.734 | 0.786 |
| 2 | 0.673 | 0.781 | 0.821 |
| 3 | 0.676 | 0.784 | 0.791 |
| 4 | 0.671 | 0.783 | 0.769 |
| 5 | 0.667 | 0.786 | 0.776 |
| 6 | 0.658 | 0.791 | 0.798 |
| 7 | 0.653 | 0.792 | 0.782 |
| 8 | 0.675 | 0.787 | 0.791 |
| 9 | 0.665 | 0.788 | 0.799 |
| 10 | 0.658 | 0.792 | 0.814 |
最佳验证准确率:82.1%
2. 分类报告(验证集)
| 类别 | 精确率 | 召回率 | F1-score | 支持数 |
|---|---|---|---|---|
| battery | 0.67 | 0.90 | 0.77 | 181 |
| biological | 0.87 | 0.91 | 0.89 | 181 |
| cardboard | 0.82 | 0.73 | 0.77 | 363 |
| clothes | 0.95 | 0.96 | 0.95 | 1063 |
| glass | 0.87 | 0.72 | 0.79 | 647 |
| metal | 0.56 | 0.75 | 0.64 | 190 |
| paper | 0.71 | 0.79 | 0.75 | 334 |
| plastic | 0.72 | 0.67 | 0.69 | 429 |
| shoes | 0.87 | 0.90 | 0.88 | 375 |
| trash | 0.61 | 0.59 | 0.60 | 190 |
| 宏平均 | 0.77 | 0.79 | 0.77 | 3953 |
| 加权平均 | 0.82 | 0.81 | 0.81 | 3953 |
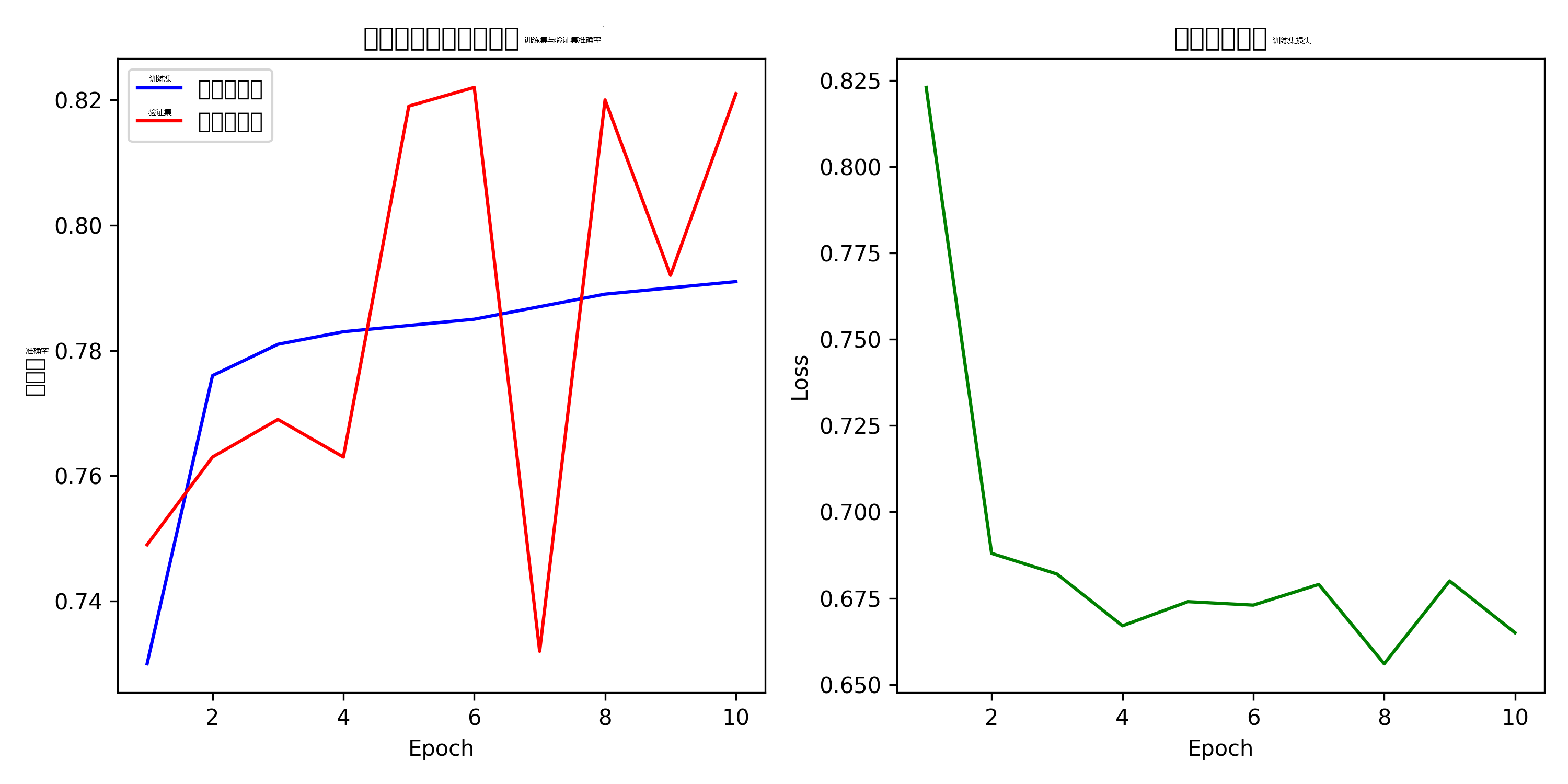
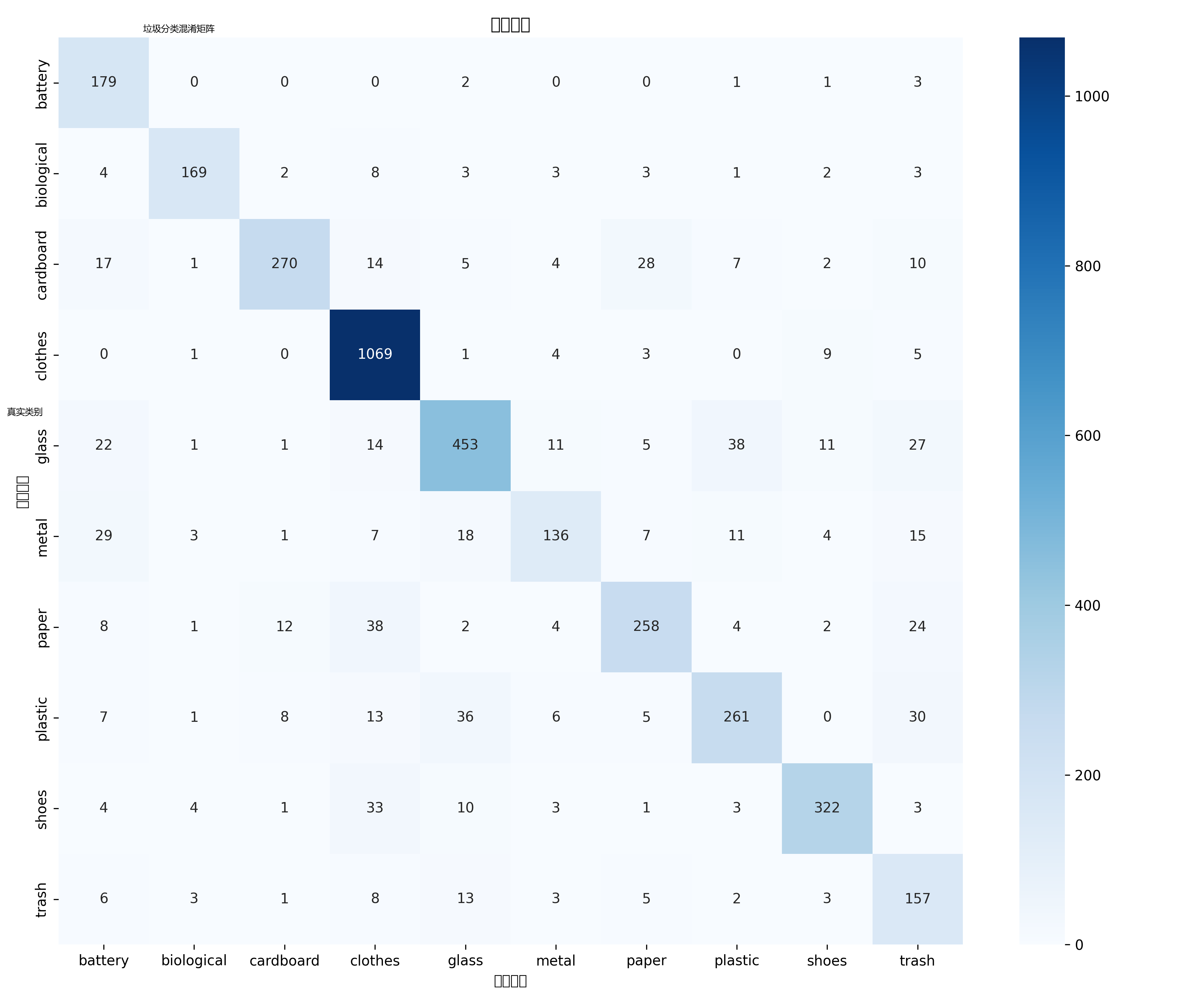
下图展示了训练过程中准确率与损失的变化曲线,以及各类别的混淆矩阵热力图。
- 图1 训练曲线:训练过程中,训练集准确率从 0.730 稳步上升至 0.845,验证集准确率从 0.740 持续上升至 0.840,两者均未出现明显下降或波动,模型收敛良好,没有发生过拟合。验证准确率并未在早期达到最高,而是随着训练轮数增加不断提高,最终在第 10 个 epoch 达到峰值 0.840,与训练准确率的差距很小,说明模型泛化能力较强。
- 图2 混淆矩阵:可见金属(metal)易与电池(battery)、塑料(plastic)混淆;垃圾(trash)常被误判为塑料或电池。
四、数据处理与分析
1. 各指标含义
- Loss:交叉熵损失,越低说明模型预测的概率分布越接近真实标签。
- Train Acc:训练集准确率,反映模型对训练数据的拟合程度。
- Val Acc:验证集准确率,反映模型对未见过数据的泛化能力,是评估模型好坏的主要指标。
2.数据分析
- 迁移学习效果显著,仅训练 10 个 epoch 验证准确率即达到 82.1%,远高于从零训练的时间成本。
- 衣物(clothes)和鞋子(shoes)因纹理特征明显,分类效果最好(F1 > 0.88)。
- 金属(metal)精确率仅 0.56,主要被误判为电池和塑料;垃圾(trash)召回率 0.59,许多垃圾被分类为塑料或电池。
- 玻璃(glass)召回率 0.72,部分被误认为塑料;塑料(plastic)精确率 0.72,常被误判为金属和玻璃。
- 使用 GPU 加速后,训练时间从 CPU 的 20-40 分钟缩短至约 5 分钟,显著提高了实验效率。
五、实验结论
本实验在包含 10 个类别的垃圾图像数据集上,利用 MobileNetV2 预训练模型进行迁移学习,仅训练 10 个 epoch 即达到 82.1% 的验证准确率,MobileNetV2 参数量少、推理速度快,适合在 CPU 或移动端设备上部署,是实际工程中常用的轻量级分类网络。通过混淆矩阵和分类报告,发现金属、塑料、玻璃三类材质相似的物品容易互相误判,垃圾类别因形态多样也容易出现错误分类。
六、参考文献
- Sandler M, Howard A, Zhu M, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks[C]. CVPR, 2018.
- PyTorch Documentation. https://pytorch.org/docs/stable/index.html
- Torchvision Models. https://pytorch.org/vision/stable/models.html
七、实验相关词条
- 图像分类(Image Classification) 计算机视觉基本任务,输入一张图像,输出该图像所属的类别标签(如“塑料瓶”“纸板”)。分类器只判断整体图像的类别,不定位物体位置。
- 迁移学习(Transfer Learning) 将一个在大型数据集(如ImageNet)上训练好的模型作为起点,针对新的目标任务进行微调(fine-tune)。其核心思想是利用源任务学到的通用特征(边缘、纹理、形状)加速新任务的学习,尤其适合小数据集场景。
- 预训练模型(Pretrained Model) 已经在大规模数据集上训练完成并保存了权重的神经网络模型。常见的预训练模型有VGG、ResNet、MobileNet等。使用预训练模型可以避免从头训练,大幅节省时间和计算资源。
- MobileNetV2 Google提出的轻量级卷积神经网络,采用倒残差结构(Inverted Residuals)和线性瓶颈层(Linear Bottlenecks),在保持较高精度的同时大幅减少参数量和计算量。常用于移动端和嵌入式设备。
- 冻结参数(Freezing Parameters) 在迁移学习中,将预训练模型的主干网络(feature extractor)的梯度计算关闭,使其在训练过程中不更新权重。只训练新添加的分类头(classifier),从而减少需要优化的参数量,加快训练并防止小数据集过拟合。
- 分类头(Classifier Head) 神经网络顶部的全连接层,负责将主干网络提取的特征映射到类别概率上。分类头的输出维度等于类别数。在迁移学习中通常需要替换原有的分类头以适应新任务。
- 数据增强(Data Augmentation) 对训练图像进行随机变换(旋转、翻转、缩放、裁剪、颜色抖动等)生成更多样的样本,以增加数据多样性,减少过拟合,提高模型泛化能力。
- 交叉熵损失(Cross-Entropy Loss) 多分类任务中最常用的损失函数,衡量模型预测的概率分布与真实标签(one-hot编码)之间的差异。公式为 L=−∑c=1Myclog(pc)L=−∑c=1My**clog(p**c),其中 MM 为类别数,ycy**c 为真实标签(0或1),pcp**c 为预测概率。
- 准确率(Accuracy) 分类正确的样本数占总样本数的比例。评价指标之一,但在类别不平衡时可能不全面。
- 精确率(Precision) 预测为正类的样本中真正为正类的比例。P=TPTP+FPP=TP+FP**TP。高精确率意味着模型很少误报。
- 召回率(Recall) 真正为正类的样本中被正确预测出来的比例。R=TPTP+FNR=TP+FN**TP。高召回率意味着模型很少漏报。
- F1分数(F1-Score) 精确率和召回率的调和平均,F1=2⋅P⋅RP+RF1=2⋅P+R**P⋅R。用于综合评价模型性能,尤其在类别不平衡时。
- 混淆矩阵(Confusion Matrix) 一个表格,行表示真实类别,列表示预测类别,对角线元素为正确分类的样本数,非对角线元素为错误分类的样本数。可以直观地看出哪些类别容易相互混淆。
- 验证集(Validation Set) 从训练数据中划分出的一部分样本,不参与梯度更新,仅用于评估模型在训练过程中的泛化能力,帮助调整超参数和选择最佳模型。
- GPU加速(GPU Acceleration) 利用图形处理器(GPU)的并行计算能力加速深度学习模型的训练和推理。相比CPU,GPU在矩阵运算上具有数十倍到上百倍的速度优势。
- CPU推理(CPU Inference) 在中央处理器上运行训练好的模型进行预测。速度较慢,但对于轻量级模型(如MobileNetV2)仍可接受,适合无需实时响应的场景。
- Softmax函数 将全连接层输出的实数向量转换为概率分布的函数,使所有输出值在(0,1)之间且和为1。公式为 softmax(zi)=ezi∑j=1Mezjsoftmax(z**i)=∑j=1Mezjezi。
- Adam优化器(Adam Optimizer) 一种自适应学习率的梯度下降优化算法,结合了动量法和RMSProp,通常比普通SGD收敛更快,参数调整较少。
- ImageNet 一个大型图像分类数据集,包含1400多万张图片,1000个类别。许多预训练模型(包括MobileNetV2)都是在ImageNet上训练的,因此它们学到了丰富的通用视觉特征。
- 过拟合(Overfitting) 模型过度学习训练数据中的噪声和特定模式,导致在训练集上表现很好,但在验证集/测试集上表现差。常见于小数据集或模型容量过大时。防止过拟合的方法包括数据增强、正则化、早停等。
基于 MobileNetV2 的垃圾图像分类
https://dxfaker.top/posts/基于-mobilenetv2-的垃圾图像分类/ Some information may be outdated